Biography
The future is distributed, cross-domain, full of complex trust and failure tolerance, and that’s where I want to be. My research is primarily in distributed systems, with emphasis on security and heterogeneous trust. I design distributed protocols and algorithms with strong guarantees, real implementations, and broad applications from medical privacy to blockchains.
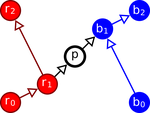
I am a Senior Research Scientist working with heliax, where I am product lead for Typhon, a next-generation heterogeneous consensus protocol. Typhon aims to enable fast and final commitments for blockchains with thousands of validators, as well as Chimera chains, a new technique for multi-chain atomic transactions with atomicity guarantees. Typhon is built on a version of Heterogeneous Paxos, which we are specifying (and formally verifying) in TLA+.
Interests
- Distributed Systems
- Consensus
- Heterogeneous Trust
- Programming Languages
Education
-
Ph.D. in Computer Science, 2019
Cornell University
-
MSc in Computer Science, 2016
Cornell University
-
BSc in Computer Science, 2012
California Institute of Technology